
Marti Figueres
My Information
LinkedIn
Resume
GitHub
Contact Information
Email: martifigueres0912@gmail.com
Phone: (469) 352-7733
Report
Summary
This analysis aims to determine the relationship between sentiment for three topics (Cybersecurity, Properties, and Sustainability) in 10-K filings and stock returns for S&P 500 companies. Using sentiment dictionaries and topic-specific contextual sentiment measures, sentiment was quantified and correlated with stock returns around their filing dates. By counting the number of positive and negatiev words in filings, specifically within 10 words of the topic-specific contextual ones, an overall grasp of the level of positive or negative sentiment towards that topic was able to be found. Then, by calculating the occurrences of positive words in general in the filings, an overeall sentiment score for each document could be calculated. Lastly, the stock returns for each document were merged with their filing date (return_t), the next two days (return_t2), the next ten days (return_t10), and also their respective sentiment score.
Findings show that ML Sentiment displayed negative correlations with return_t, contrasting with Garcia, Hu, and Rohrer’s findings. Similarly, Cybersecurity and Sustainability show weak negative correlations to the return, while Properties show weak positive correlations. Negative ML Sentiment across return windows showed a shift from negative (short-term) to positive (long-term) correlations, suggesting possible reversals in market reaction as time passes. Interestingly, the only notable correlation was between the overall sentiment score and that of the negative cybersecurity score (-0.27). This is likely from the weight of the negative cybersecurity, being that a large portion of words in many of the documents deal with cybersecurity in a contextually negative way, causing the overall sentiment score to go up as that score only measures the overall positive context words in a document.
Data Selection
Sample
The sample consisted of S&P 500 companies as of 2022, with their 10-K filings and corresponding stock return data from CRSP. The final analysis sample includes firms with sentiment scores (overall and topic-wise), filing dates, and stock return data
Return Variables
return_t: Stock return on the filing date
return_t2: Cumulative stock return from the filing date to two days after
returnt_10: Cumulative stock return from three days after the filing date to ten days after
These variables were all built by filtering CRSP Data. For each firm in the merged_df, the corresponding sstock return data was filtered from the CRSP dataset using hte firms ticker symbol. The filling date was used as the reference point for calculating returns, as seen in the code below.
#filter crsp df to get row corresponding to current firm's ticker
firm_returns = crsp[crsp['ticker'] == row['ticker']]
event_day = firm_returns[firm_returns['date'] == filing_date]
#again, make sure things (event_day) arent empty
#pd.Timedelta allows for arithmetic operations on dates/times
if not event_day.empty:
return_t = event_day['ret'].values[0]
return_t2 = firm_returns[(firm_returns['date'] >= filing_date) & (firm_returns['date'] <= filing_date + pd.Timedelta(days=2))]['ret'].sum()
return_t10 = firm_returns[(firm_returns['date'] >= filing_date + pd.Timedelta(days=3)) & (firm_returns['date'] <= filing_date + pd.Timedelta(days=10))]['ret'].sum()
merged_df.at[index, 'return_t'] = return_t
merged_df.at[index, 'return_t2'] = return_t2
merged_df.at[index, 'return_t10'] = return_t10
Sentiment variableles
LM_Positive/Negative: Counts of positive and negative words from the Loughran-McDonald (LM) Dictionary
- LM Positive: 347 words
- LM Negative: 2345 words
Found by loading the LM lists from the Master dictionary
file_path = "inputs/LM_MasterDictionary_1993-2021.csv" # Update with actual path
df = pd.read_csv(file_path)
LM_positive = df[df['Positive'] > 0]['Word'].tolist()
LM_positive = [e.lower() for e in LM_positive]
LM_negative = df[df['Negative'] > 0]['Word'].tolist()
LM_negative = [e.lower() for e in LM_negative]
ML_Positive/Negative: Counts of positive and negative words from the ML unigram dictionary
- ML Positive: 75 words
- ML Negative: 94 words
Found by importing the list from our inputs folder:
with open('inputs/ML_negative_unigram.txt', 'r') as file:
BHR_negative = [line.strip().lower() for line in file]
with open('inputs/ML_positive_unigram.txt', 'r') as file:
BHR_positive = [line.strip().lower() for line in file
Topic Specific Sentiment: Topic-specific sentiment measures for Cyberesecurity, Properties, and Sentiment. Constructed using the NEAR_regex function to find topic-related words within a proximity of 10 words to sentiment words, using Partial = True to allow for partial matches allowing for a bit more leeway in the contextual words while still being similar to the topic word.
#use regex to find nearby topic words and their positive/negative sentiment
for topic, words in topic_words.items():
pos_output = NEAR_finder(words, ML_positive, document, max_words_between=10)
firm_results[f'{topic}_Positive'] = pos_output[0]
neg_output = NEAR_finder(words, ML_negative, document, max_words_between=10)
firm_results[f'{topic}_Negative'] = neg_output[0]
Topic Selection
The three topics — Cybersecurity, Properties, and Sustainability — were chosen due to their relevance to modern corporate disclosures and their potential impact on investor decisions. These topics are frequently discussed in 10-K filings and are of strategic importance to firms.
Summary Statistics
Document Length
- Min: 4,028 words
- Max: 158,298 words
- Mean: 42,360 words
Sentiment Scores
- Min: 0.011439
- Max: 0.054441
- Mean: 0.033393
Returns
Return_t
- Min: -0.242779
- Max: 0.162141
- Mean: 0.001244
Return_t2
- Min: -.0288377
- Max: 0.186864
- Mean: 0.006969
Return_t10
- Min: -0.597995
- Max: 0.395649
- Mean: -0.0073333
Contextual Sentiment
Though no variable is constant, overall, there is little variation among the three return dates. Industries like real estate tend to show higher positive sentiment for properties, which aligns with expectations, however, industries in technology tended tt talk about cybersecurity more negatively, displaying higher negative sentiment scores. Both positive and negative sentiment numbers increased greatly (sometimes 10-fold) for industries that are topic-specific, showing that the regex function captures meaningful information.
Caveats
Some caveats to this data the reader should be aware of revolve around sample limitations. This sample is limited to S&P 500 firms in 2022, which may not generalize to smaller firms or firms before COVID-19. Another caveat that should be said with any model is causality, in that while this analysis tries to identify correlations, it cannot establish causality between sentiment and returns. Also, not all language or filler text may have been removed in the documents, which can dilute the sentiment signal. Laslty, while the contextual words for the three topics may have been extensive, it was not exhaustive and I’m sure there were many words relating to the topics that would have flagged sentiment which I missed.
Results
Table: Correlation of Each Sentiment Measure Against Return Measures
| Sentiment Measure | return_t | return_t2 | return_t10 |
|---|---|---|---|
| LM_Positive_Total | -0.094905 | -0.103082 | -0.029153 |
| LM_Negative_Total | -0.049993 | -0.057039 | -0.056119 |
| ML_Positive_Total | -0.042430 | -0.032589 | -0.005833 |
| ML_Negative_Total | -0.036529 | -0.036205 | 0.028079 |
| Cybersecurity_Positive | -0.009735 | -0.030446 | -0.118316 |
| Cybersecurity_Negative | -0.019586 | -0.035941 | -0.096455 |
| Properties_Positive | 0.036123 | 0.020058 | 0.007866 |
| Properties_Negative | 0.044406 | 0.025765 | 0.024222 |
| Sustainability_Positive | -0.031326 | 0.000547 | 0.178849 |
| Sustainability_Negative | -0.015515 | 0.013134 | 0.190426 |
Scatterplot of each sentiment measure against return measures
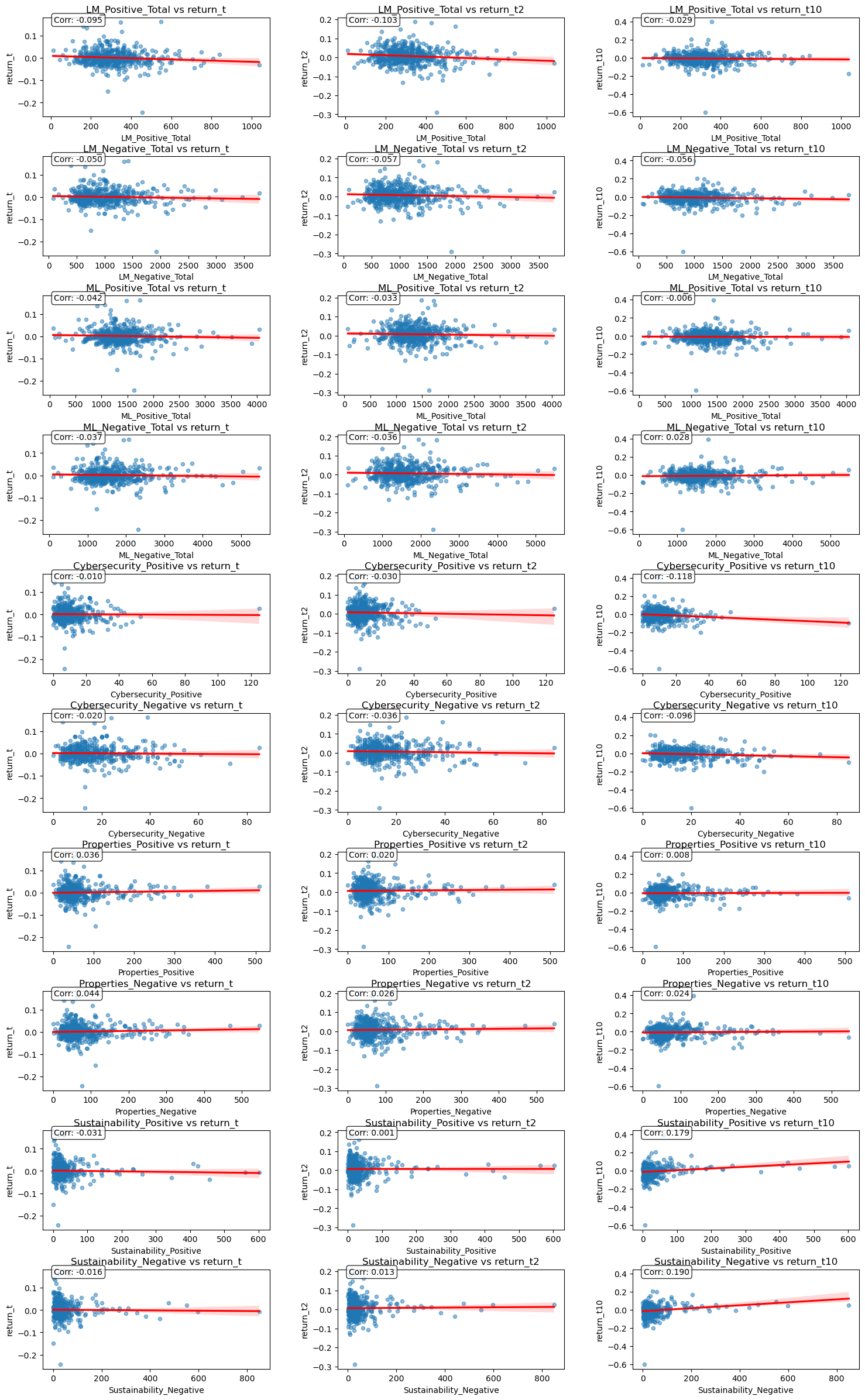
Discussion Topics
1: Comparison of LM Sentiment vs ML Sentiment, focusing on return_t
LM Sentiment Variables:
- LM Positive: The correlation with
return_tis negative (-0.09491). - LM Negative: The correlation with
return_tis also negative (-0.04993).
ML Sentiment Variables:
- ML Positive: The correlation with
return_tis negative (-0.04243). - ML Negative: The correlation with
return_tis negative (-0.03653).
Comparison:
- Both LM and ML sentiment measures show negative correlations with
return_t, suggesting that higher positive or negative sentiment in 10-K filings is associated with lower returns on the filing date. - The magnitudes of the correlations are similar, with LM sentiment measures showing slightly stronger negative relationships than ML sentiment measures.
2. Contrast with Garcia, Hu, and Rohrer (ML_JFE.pdf):
In Table 3 of their paper, they find that ML positive sentiment is positively correlated with returns, while ML negative sentiment is negatively correlated. This contrasts with my findings, where both positive and negative sentiment measures (LM and ML) show negative correlations. However, they did agree with my findings that LM positive sentiment showed a negative correlation, while LM negative sentiment showed a negative correlation in the first filing period, yet went positive in filing periods 5 and 6.
- Possible Reasons for Differences:
- Sample Differences: My analysis was limited to S&P 500 firms in 2022, while their study included a much larger sample of firms over multiple years. The smaller sample size in my analysis may not capture the full variation in sentiment and returns.
- Control Variables: Their study includes additional controls like firm size, profitability, and industry, which may isolate the effect of sentiment more effectively.
- Sentiment Calculation: Differences in how sentiment is calculated could also contribute to the discrepancy
3. Contextual Sentiment Measures)
Cybersecurity Sentiment:
- Cybersecurity Positive: Correlation with
return_tis negative (-0.09735). - Cybersecurity Negative: Correlation with
return_tis negative (-0.01959).
Properties Sentiment:
- Properties Positive: Correlation with
return_tis positive (0.03612). - Properties Negative: Correlation with
return_tis positive (0.04441).
Sustainability Sentiment:
- Sustainability Positive: Correlation with
return_tis negative (-0.03133). - Sustainability Negative: Correlation with
return_tis negative (-0.01552).
Discussion:
- Cybersecurity and Sustainability: Both show weak negative correlations with
return_t. This suggests that higher sentiment (positive or negative) in these topics is associated with slightly lower returns on the filing date. - Properties: Shows weak positive correlations, suggesting that higher sentiment in this topic is associated with slightly higher returns.
Economic Argument for Value Relevance:
- Cybersecurity: Negative sentiment may reflect concerns about data breaches or vulnerabilities, which could lead to lower investor confidence and stock prices.
- Sustainability: Negative sentiment may indicate concerns about environmental risks or regulatory scrutiny, which could negatively impact returns.
- Properties: Positive sentiment may reflect optimism about real estate investments or development projects, which could boost investor confidence and stock prices.
4. Differences in Sign and Magnitude
Sign Differences:
- LM and ML Sentiment: Both show negative correlations with
return_t. - Contextual Sentiment: Cybersecurity and Sustainability show negative correlations, while Properties shows positive correlations.
Magnitude Differences:
- The magnitudes of the correlations are generally small, with Properties sentiment showing slightly stronger positive relationships.
Speculation on Why:
- Properties: Real estate and property-related disclosures may have a more direct impact on firm valuation, leading to stronger positive correlations.
- Cybersecurity and Sustainability: These topics may involve more complex or long-term risks, leading to weaker or negative correlations with short-term returns.